Type I Diabetes
What is Type I Diabetes?
Type I diabetes is a chronic condition where the pancreas is unable to produce adequate or no insulin. Insulin is vital for internal bodily functions because it primary job is to turn sugar, otherwise known as glucose, into energy.
There is no known cause or prevention for Type I diabetes. What makes it more difficult for diabetics are the potential serious complications such as heart disease, nerve damage, kidney damage and more.
According to Juvenile Diabetes Research Foundation
1,600,000
Type I diabetics in U.S.
Learn More about Type I DiabetesControlling Blood Glucose
Controlling blood glucose is a continuous challenge for Type I diabetics. Poor control of blood glucose negatively impacts lifestyle, and most seriously, impacts health and well-being. If Blood Glucose becomes elevated above acceptable levels, this could lead to Hyperglycemia resulting in symptoms such as:
- Fatigue
- Headache
- Shortness of breath
- Weakness
- and much more
Our Mission
Improve diabetes management for a better life by predicting blood glucose sensitivity
Dataset
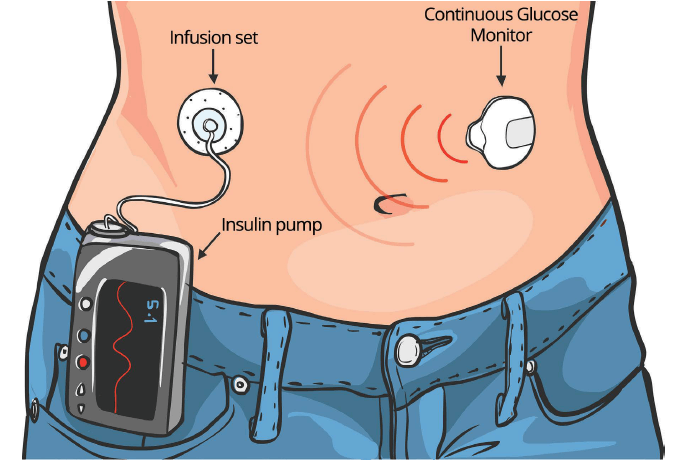
OpenAPS Dataset
Open APS Data Commons is an open source tool that is designed to gather data from continuous glucose monitoring (CGM) and insulin pump devices in an effort to analyze data automatically to give users vital information. For this dataset, users submitted data from NightScout CGM.
The dataset is as recent as August 2021 which contains 112 GB of data over a 5 year period prior to that month. Users information was voluntarily submitted to OpenAPS and made avaliable to our project team in order to develop our machine learning models. (see FAQ for Privacy Information)
The visual to the right shows all subjects from the OpenAPS dataset averaged over an hourly period to demonstrate the flow of blood glucose throughout a single day
Learn more about OpenAPS Data Commons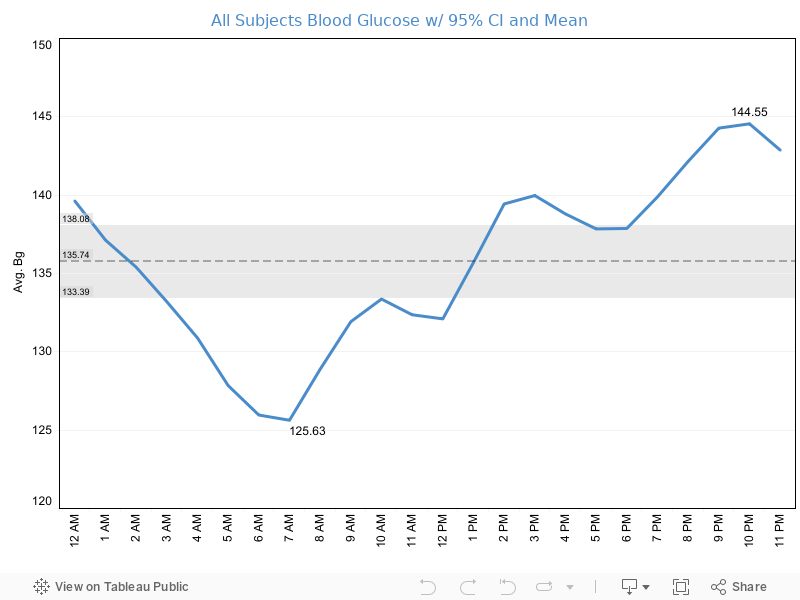
NightScout CGM
NightScout is an open source project that continuously collects blood glucose, as well as other data points. Via a transmitter and receiver device, NightScout is able to store this information and, with users permissions, load that data to a website that provides users an analytical summary of their blood glucose status. This information can be collected as frequently as every 5 minutes!
The NightScout project is an amazing tool and the analytical services of platform are free! We recommend checking out their website below!
Learn more about NightScout ProjectFeatures
After data transformation, our project team narrowed data down to core features to inform our machine learning models:
- Blood glucose (target variable)
- Insulin
- Carbs
- Timestamp of blood glucose Entry
- Lag of blood glucose
Models
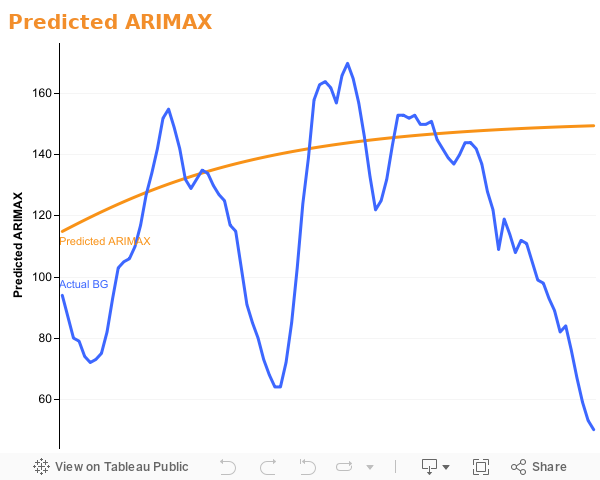
Predicted ARIMAX
To establish baseline performance we are using a classical model known as ARIMAX. In this model, we use the last 12 examples of a single subjects reported blood glucose entries. The figure shown shows the predicted blood glucose values over the next 8 hours period. The data used for this model is from a randomly sampled subject.
Results/Conclusion
As you can see from the figure, the ARIMAX model follows the general trend of actual blood glucose values (shown as blue line), but is unable to accurately predict the blood glucose level. Without an accurate blood glucose value to make decisions on, diabetics would not be able to utilize, or even trust this type of model, thus we move on to more advanced models.
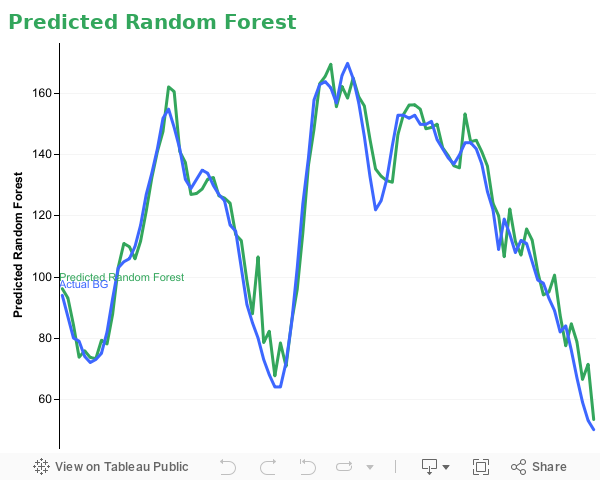
Predicted Random Forest
Here we look at a model named Random Forest. This model takes more complex approach to prediction unlike the ARIMAX model we described above. The Random Forest model includes the last 12 blood glucose entries, as well as the last 12 insulin and carb entries for its prediction. The model, like ARIMAX, also attempts to predict blood glucose over the next 8 hour period. The data used for this model is from a randomly sampled subject.
Results/Conclusion
As shown in the figure (line shown in green), the Random Forest model follows the trend of actual blood glucose more closely than ARIMAX. It is safe to say that Random Forest is able to accurately predict blood glucose. While the model is accurate, there are points of which inaccurate spike occur but those are quickly corrected.
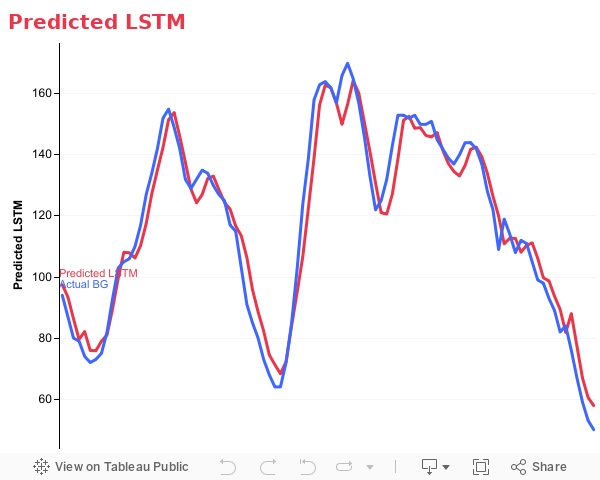
Predicted LSTM
Similarly to the Random Forest model, our LSTM model using the last 12 blood glucose entries, as well as the last 12 insulin and carb entries to predict blood glucose levels. Like ARIMAX and Random Forest, this model attempts to predict blood glucose over the next 8 hour period. The data used for this model is from a randomly sampled subject.
Results/Conclusion
As you can see in the Predicted LSTM figure (line colored in red), the LSTM model follows the trend of actual blood glucose levels very well and is able to accurately predict blood glucose levels. One of the key differences between Random Forest and LSTM is its stability. As you can see in the figure, LSTM has less deviation, or spikes, from the actual blood glucose. But generally, Random Forest and LSTM are quite similar.
Models Conclusion
In the figure labeled "All Model Results", you can see all of our individualized models in comparison to each other and the actual blood glucose levels. Random Forest and LSTM models provide the best results for accurately predicting blood glucose values. While this website provides a simplified overview of our models, we recommend taking a look at our research paper for more details into all of our project work!

Project Team
Special Thank You to Puya Vahabi and Alberto Todeschini

Spencer Weston
sweston@ischool.berkeley.edu

Khyati Tripathi
kntripathi@ischool.berkeley.edu

Javier Romo
jromo@ischool.berkeley.edu
Frequently Asked Questions
What privacy did users have after donating their data to OpenAPS?
The OpenAPS dataset did not contain any personal information or demographics. Subjects were identified by a randomly generated identifier. From our review of the dataset, their is no data point that can be utilized or reversed engineered to identify names, locations, or any other identifiers from .